

In the world of DFIR, logs are invaluable resources. They are the fingerprints left behind that allow us to reconstruct actions taken on a system, identify potential threats, and trace attacker movements. One of the keys to success in conducting an effective digital investigation on a computer system is to know what happened/is happening on the system. Computer systems and applications generate large amounts of logs to measure and record information for the duration of the monitoring period. These logs can provide solid forensic evidence to reveal the activities of a malicious user and discover how, when, and where an incident occurred and help in attributing nefarious activities.
A log is a collection of event records. An event record is a collection of event fields that describe a single event together. An event field describes one characteristic of an event. Examples of an event field include date, time, source IP, user identification, and host identification. An event is a single occurrence within an environment, usually involving an attempted state change. An event usually includes a notion of time, the occurrence, and any details that explicitly pertain to the event or environment that may help explain or understand the event’s causes or effects.
Linux Log Files
Linux log files are collections of event records or activities generated by applications, system services, and the kernel within the GNU/Linux operating system. , Although each distribution has its
own way of naming and dividing up the log files. For the most part, Linux packages send their logging information to files in the /var/log directory.

It should be noted that the content of the above directory does not look the same across Linux distributions. They might also look different between different versions of the same distribution. Each log is specific to certain services or events, which allows for easier targeting of the logs relevant to the task at hand. Since most logs are text files, they can be viewed or parsed with standard tools such as cat, grep, tail, and Perl.
Syslog
For most Linux systems, syslog is the primary logging service. It runs as a background service and listens for, and receives log messages from various processes on the system and then routes the log messages to different destinations based on the configuration made by the system administrator. Syslog is also a network protocol that allows routing logs over the network to a Syslog service on another host and is widely used as well in many security products, such as Firewalls, and Intrusion Detection Systems (IDS). This is useful for aggregating your logs together into a SEIM tool or other log analysis platform—collected logs have huge value during an investigation. Syslog harks from the days of the early Unix sendmail program in the 1980s and has since become the de facto logging standard for IT infrastructure.
Syslog provides a way for processes to send logs to a central log file, local or remote, using a standardized format and severity levels. The syslog architecture and network protocol are defined in RFC 5424. The key components of syslog are explained as follows.
- Timestamp - Date and time of event
- Hostname - Machine generating the log
- Facility - Program, process, or component that generated the log.
- Log level - Severity or importance, like informational (INFO), warning, or error
- Message Body - Event details.

Syslog Daemon
The syslog format is used by a variety of tools that vary in function and complexity and are generally all collectively called syslog daemons. These daemons include the basic syslog tool and more advanced variants such as syslog-NG (the NG means “next generation”) and rsyslog. rsyslog has benefitted greatly from the work done on syslog and syslog-NG. The syslog daemon is the core service responsible for managing and storing logs on the system. It listens for incoming log messages from different system components and applications and directs them to the specified log files.
Facilities
The facility describes the part of the system or application that generated the log message. It categorizes log messages by their source or origin. Some operating system daemons and other common application daemons have standard facilities attached to them. The mail and kern facilities are two good examples, being mail-related event notification messages and all kernel-related messages, respectively. Other processes and daemons that do not have a specified facility can use the local facilities, which range from local0 to local7. RFC 5424 documents 24 syslog message facilities:
Numerical Code | Facility | Description |
0 | kern | The kernel |
1 | user | user processes or applications |
2 | log entries related to mail servers and email processing | |
3 | daemon | system daemons or background services |
4 | auth | security and authorization-related (e.g., ssh logins) |
5 | syslog | Syslog internal messages |
6 | LPR | BSD line-printer daemon |
7 | news | usenet news system |
8 | UUCP (obsolete) | for the (ancient) UUCP (unix-to-unix copy) service |
9 | Cron | the cron daemon |
10 | authpriv | similar to auth , logged to secure file |
11 | ftp | FTP daemon |
12 | ntp | NTP subsystem |
13 | security | Log audit |
14 | console | Log alert |
15 | solaris-cron | Scheduling daemon |
16-23 | Local0-local7 | Reserved for locally defined messages. Used for local/other daemons |
One internal facility called 'mark' is often implemented separately from the syslog standard. The mark syslog facility is a feature of the syslog logging system that generates periodic logging messages marked as --MARK--. These messages are not related to any specific service or process; instead, they serve as 'heartbeat' entries to indicate that the syslog service is running properly and actively writing to the log files. In a forensic examination, missing or irregular mark entries can hint at log tampering or syslog disruptions.
Severity
Each Syslog message includes a severity level, indicating its priority or urgency. The severity level can be represented as either a numeric value or a text label. There are eight severity levels, with zero being the most severe.
Numerical Code | Severity |
0 | Emergency: the system is unusable |
1 | Alert: action must be taken immediately |
2 | Critical: critical conditions |
3 | Error: error conditions |
4 | Warning: warning conditions |
5 | Notice: normal but significant condition |
6 | Informational: informational messages |
7 | Debug: debug-level messages |
Syslog Configuration
The syslog configuration can be invaluable for forensic examiners when investigating incidents on Linux-based systems. The syslog service, typically managed by rsyslog or syslog-ng handles logging configuration through configuration files. These files control how logs are collected, formatted, and stored. Key configuration options include:
- Log facility and priority - This has been discussed in the previous section. This can be customized in syslog configurations to determine what events are recorded.
- Log Destinations - The syslog configuration defines where logs are stored (e.g., specific files like /var/log/auth.log for authentication logs) and how they are retained. It can also direct logs to external servers for centralized logging.
- Remote Logging - Syslog supports sending logs to remove servers, often over TCP or UDP. Remote logging is crucial for forensic purposes as it ensures that logs are retained even if the system is compromised or if local logs are altered or deleted by an attacker.
- Custom Filters and Rules - Syslog allows the creation of filters and rules that determine what events are logged, where they are logged, and if specific entries should trigger alerts. This helps examiners prioritize logs related to certain behaviors or applications.
Common syslog daemon configuration file locations are listed below. These are plaintext files that can be read via any text editor.
- /etc/syslog.conf
- /etc/rsyslog.conf
- /etc/rsyslog.d/*.conf
- /etc/syslogng.conf
- /etc/syslogng/*

The left column uses a combination of facility.priority to select log messages. The facility reveals information about where the log came from. For example, authpriv messages are authentication or security messages that are supposed to be kept private (for administrators only). Messages like these are used to track user logins, logouts, and privilege escalations and therefore are very interesting to us. Priority ranges from debug (lowest) all the way up to emergency (highest). Priorities are organized in an escalating scale of importance. They are debug, info, notice, warning, err, crit, alert, and emerg. Each priority selector applies to the priority stated and all higher priorities, so mail. err indicates all mail facility messages of err, crit, alert, and emerg priorities. Administrators can use the wildcard selectors * and none. The “*” is a wildcard that means 'match any facility or priority'. Additionally, they can use two other modifiers: = and !. The = modifier indicates that only one priority is selected; for example, cron.=crit indicates that only cron facility messages of crit priority are to be selected. The ! modifier has a negative effect; for example, cron.!crit selects all cron facility messages except those of crit or higher priority. The two modifiers can be combined to create the opposite effect of the = modifier so that cron.!=crit selects all cron facility messages except those of critical priority. Only one priority and one priority wildcard can be listed per selector.
The destination for the log messages can be a file path or a remote hostname (or IP
address) given as “@
Here is an example of a log entry generated by syslog in a Linux web server forensic image:

Each log message starts with a date/time stamp in the system’s default time zone, the name of the host where the log message was generated, and the process name and usually the process ID number (in square bracket) of the software that generated the log, and the message details. The format of the date/time stamp is very regular and can be searched for. This is a useful trick when trying to recover deleted log messages from unallocated space. You can use the Unix regular expression '[A-Z][a-z]* *[0-9]* *[0-9]*:[0-9]*:[0-9]* *’ to search for the standard date/time stamp (uppercase letter, lowercase letters, spaces, number, spaces, number, colon, number, colon, number, spaces).
During a
forensic examination, it is useful to check if and how log files are rotated and
retained over time. Most Linux systems use log rotation to manage retention as logs grow
over time. As system processes and applications run, logs grow continually, sometimes rapidly creating large files that culminate in poor system performance. Log rotation helps by periodically archiving, compressing, or deleting older logs while keeping recent logs accessible. A
common software package for log rotation is logrotate, which manages log retention
and rotation based on a set of configuration files. The default configuration
file is /etc/logrotate.conf, but packages may supply their own logrotate configuration and save it in /etc/logrotate.d/* during package installation. Traditionally, Linux systems will keep
four weeks of old log files in addition to the log file that is currently being written to by
Syslog. So you will find about a month's worth of logs under /var/log. If
/var/log/secure is the primary file name, you will find the older logs in files named secure.1 through secure.4, with secure.4 holding the oldest log message.
# A sample logrotate.conf file
weekly
rotate 4
create
dateext
include /etc/logrotate.d
/var/log/wtmp {
monthly
create 0664 root utmp
minsize 1M
rotate 1
}
/var/log/btmp {
missingok
monthly
create 0600 root utmp
rotate 1
}
The sample file above contains the global options that logrotate uses to handle log files. Other options that might be encountered are shown in the table below.
|
Option |
Description |
|
daily |
Logs are rotated on a daily basis |
|
weekly |
Logs are rotated on a weekly basis |
|
monthly |
Logs are rotated on a monthly basis |
|
compress |
Old log files are compressed with gzip |
|
create mode owner group |
New log files are created with a mode in octal form of 0700 and the owner and group (the opposite is nocreate). |
|
Ifempty |
The log file is rotated even if it is empty |
|
include directory or filename |
The contents of the listed file and directory to be processed by logrotate are included. |
|
mail address |
When a log is rotated out of existence, it is mailed to address. |
|
nomail |
The last log is not mailed to any address |
|
missingok |
If the log file is missing, it is skipped and logrotate moves on to the next without issuing an error message. |
|
rotate count |
The log files are rotated count times before they are removed. If count is 0, old log files are removed, not rotated |
|
size size[M,k] |
Log files are rotated when they get bigger than the maximum size; M indicates size in megabytes, and k indicates size in kilobytes. |
|
sharedscripts |
Prescripts and postscripts can be run for each log file being rotated. If a log file definition consists of a collection of log files (for example, /var/ log/samba/*) and sharedscripts is set, then the pre-script/ post-scripts are run only once. The opposite is nosharedscripts. |
Forensic examiners should be aware that syslog messages have some security issues that may affect the evidential value of the resulting logs. Thus, all logs should be analyzed with some degree of caution:
- Programs can generate messages with any facility and severity they want.
- Syslog messages sent over a network are stateless, unencrypted, and based on UDP, which means they can be spoofed or modified in transit.
- Syslog does not detect or manage dropped packets. If too many messages are sent or the network is unstable, some messages may go missing, and logs can be incomplete.
- Text based logfiles can be maliciously manipulated or deleted.
Syslog-Related Logs
The auth.log is a log file that records entries for all authentication attempts. It plays a critical role in tracking security-related activities as it logs user authentications, login attempts (successful and failed), sudo commands, and SSH connections. The auth.log file is typically found at /var/log/auth.log on Debian-based distributions and /var/log/secure in Red-Hat distributions. It is used to monitor access and identify possible security incidents such as privilege escalations, and brute-force attacks.

On Debian-based systems, the kern.log file contains messages about
what's going on with the Linux kernel. It can be found at the location /var/log/kern.log. Red Hat-based systems do not have this file. Instead, Red
Hat systems send their kernel messages to the /var/log/messages file. The kern.log file is useful for diagnosing hardware issues, kernel panics, driver problems, and other low-level system issues. kern messages will contain information about devices on the system, including USB devices
as they are plugged in (useful for USB forensics). kern messages also can contain logs from the Linux Netfilter firewall, aka IP Tables. So,
if you want to see whether any suspicious network packets have been blocked,
this is the place to look.

The boot.log file stores the messages that are emitted by the system during boot. It is located at /var/log/boot.log. It primarily records messages generated during the system initialization phase, such as the loading of services, hardware initialization, and startup scripts. Understanding and analyzing this file can help identify boot issues or suspicious activities during system startup.

In analyzing the boot.log file, adhere to the following steps:
- Look for entries marked [FAILED], [ERROR], or [DEPENDENCY FAILED] to identify failed services or misconfigurations.
- Identify any delays in the boot process by looking for gaps in timestamps. If your system uses journalctl, check for delays.
- Unusual entries, such as unexpected services starting or modifications to the normal boot sequence, could indicate malicious activity. Pay attention to:
- New services not previously seen.
- Unknown kernel modules being loaded.
- Failed authentication attempts during startup.
- Cross-reference entries in the boot.log with
/var/log/syslogor/var/log/messages(as the case may be) for a broader context.
The lpr.log file records details about printing activities. It can give you a record of any items that have been printed from the machine. The lpr.log file is not always present on modern Linux distributions, as many have transitioned to CUPS (Common Unix Printing System). However, if LPR is installed and configured, the log file may be found in standard logging directories such as /var/log/lpr.log, or /var/spool/lpd. Analyzing the lpr.log file can provide insights into various forensic scenarios. For example, corporate espionage cases often involve the criminal printing out sensitive documents. Having a record of exactly what was printed, when, and which user printed it can be very useful. In modern systems, records of printing activities can be found in /var/log/cups.

There are other types of logs you may run into on Linux systems that can be very useful in investigations.
Last Login History
The wtmp file keeps a record of login sessions, reboots, and system shutdowns. It helps forensic examiners understand user activity, especially for tracking who accessed a system and when. The wtmp file is located at the /var/log/wtmp. It is a fairly generic log file in that new entries are simply added to the end of the file. However, the wtmp file is maintained in a binary format, unlike most text-based Linux log files, so it cannot be read with utilities like cat or less. The last command is the primary tool for reading the wtmp file. last shows the newest logins first.

The above output shows remote logins by the "mail" account from IP address 192.168.210.131 on October 5, 2019. We can also see a history of other successful logins, shutdowns, and reboots at different times.
The btmp file is also a binary log file that records failed login attempts. It assists forensic examiners in identifying suspicious activity, unauthorized access attempts, and brute-force attacks. The btmp file is located at /var/log/btmp.
.png)
Just like the wtmp file, the last command is the primary tool for reading the btmp file. The artifacts of interest when analyzing btmp files are:.
- Username - This shows the account that attempted to authenticate. It should be noted that the btmp file does not log non-existent usernames. So failed attempts to guess usernames will not show up.
- Terminal - If the login attempt emanates from the local system, the terminal will be marked as :0. You should pay attention to login attempts from unusual or unexpected terminals.
- IP Address - This shows the remote machine where the login attempt originated. This is useful in identifying the source of a potential attack.
- Timestamp - This provides the start and end time of the authentication event. If the system does not log the end time, it will appear as "gone" in the log. These incomplete events could signal abnormal activity.
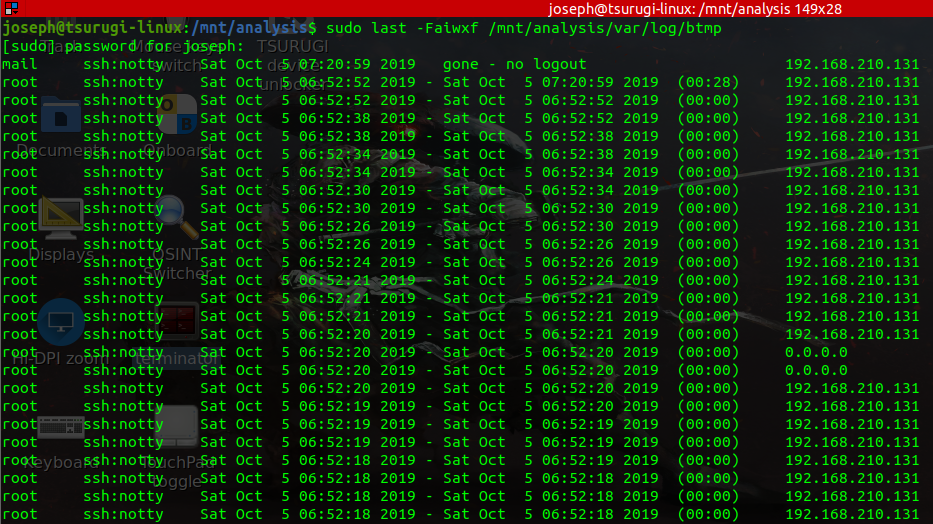
The result above is suggestive of suspicious activity. We can see a failed login for user “mail” and multiple failed “root” logins, all originating from the same IP address 192.168.210.131 on Saturday October 5, 2019.
The lastlog contains similar information to that in wtmp, but it records only the time of last login for each user.. It helps track when each user last accessed the system and is often used for auditing, monitoring, and security purposes. It is typically found at /var/log/lastlog. It is a sparse, binary file that is indexed by UID. It will stay smaller if the UIDs are assigned in some kind of numeric sequence. lastlog doesn’t need to be rotated because its size stays constant unless new users log in. The file is read with the lastlog command,
which simply goes line by line through the password file and dumps the lastlog record for
each UID it finds there. The biggest problem, however, is that the format of the lastlog file is highly variable.
The version of Linux you are running as well as the processor architecture that the
lastlog file was written on can affect the size of the lastlog records and impact your
ability to read the file.
Web Server Logs
Investigating web server logs is a critical part of DFIR, especially when dealing with potential web server intrusions. Web server logs are text files generated by web servers (such as Apache, NGINX) that record details of client requests, server responses, and errors. These logs provide a historical record of the interactions between users and the server. These logs include:
- Access logs - Records client requests to the server.
- Error logs - Captures errors encountered during client processing.
- Custom logs - This may include specific details depending on server configuration.
The web server logs are typically found in the following locations:
/var/log/httpd/var/log/apache2/*- Apache HTTP Server/var/log/nginx/*- NGINX
The first Web server was developed in 1990 before syslog had really become a standard, so the National Center for Supercomputing Applications (NCSA) developed a log format for their Web server. This log format remains in use today. The log format, called the Common Log Format, has the following format:
host identity userid date request status sizeWhile the Common Log Format is used across many Web servers, it is not the only log format that is available. Perhaps more common is the W3C Extended Log Format. The extended log can be configured per server, by the server administrator, by providing a format to the server to indicate, what log messages should look like. An example of the W3C extended log format is below.

- IP Address - This is the IP Address of the client machine
- rfcname and logname - These are the remote and authenticated user respectively. The remote user was supposed to be determined using the old “ident” protocol, which is no longer supported. The authenticated user is only known if the user is using HTTP Basic or Digest auth or some other built-in authentication strategy in the web server (hint: this never happens in modern web apps). So these fields are almost always “-”, indicating no information.
- Date and time zone - When the request was received
- Page Access Method - This is the HTTP request method "GET/".
- Path of Requested File - This is the full path of the requested resource.
- HTTP Version - This signifies the protocol and its version.
- Server Response Code - This is the HTTP status code of the server response. 200 is success, 3xx is a redirect to another URL, 4xx is client error (like “404 Not found”—the client asked for something that didn’t exist), 5xx is server error (can sometimes indicate an exploit that causes the server to blow up).
- Bytes Received - Size of the response in bytes.
- Referrer URL - This is the source of the request. HTTP Referrer information is an optional field. It may not be present in the default log format.
- User Agent String - The user-agent string from the software making the web request. Useful for tracking malware that uses unique user-agent strings. Like the referrer, this field is optional.
In forensic analysis, the following artifacts should be monitored:
- Look for unusual or malicious HTTP methods such as OPTIONS, DELETE, or PATCH, which may indicate scanning tools or attempted exploits. Webshells often use POST requests to execute commands or upload files.
- Investigate the HTTP 200 response code to identify successful requests. Search for unusual or non-existent filenames (like 210.php) which are commonly used for webshells.
- Adversaries may use default or uncommon User-Agent strings, which can help trace their activity. Although this value can be spoofed, it is still valuable for identifying patterns, especially for internal servers.
A truncated output from viewing the content of the access.log file in a compromised web server is given below.

In the above image, POST requests can be seen. We can observe a blob of base-64 encoded strings sent from the IP Address 192.168.210.131 to the web server. Extracting this long string and decoding it revealed the following output. A PHP script doing some kind of network activity. A further examination of the code reveals that it is in fact a reverse web shell written in PHP, and is used to connect to the IP address 192.168.210.131 on port 4444.
Error logs are also important as they provide insights into issues or anomalies that may indicate security incidents, misconfigurations, or unauthorized activities. Error logs often capture application errors or stack traces triggered by malformed requests, revealing attempts to exploit server vulnerabilities like SQL injection (SQLi), Remote Code Execution (RCE), and Cross-Site Scripting (XSS). Also, attackers often upload scripts to compromised servers. If these scripts cause errors (for example, due to syntax errors, or misconfigurations), they are logged. When investigating intrusions, error messages appearing before an incident can indicate preattack reconnaissance or prior failed attempts. .

In the first and second lines on the marked portion of the above image, some base64-encoded exploit code can be seen. The third and fourth line shows the attacker trying to exploit the update.php script.
Database Logs
Investigating database logs is a critical aspect of database forensics and incident response. Logs can reveal unauthorized access, SQL injection attempts, configuration changes, or other anomalies. Each database management system stores logs in specific locations. Common paths include:
/var/log/mysql/*or/var/lib/mysql/*- MySQL. Key logs include error.log, slow-query.log, and general.log/var/log/postgresql/*- PostgreSQL. The key log is postgresql-<version>.log/var/log/mongodb/*- MongoDB/var/opt/mssql/log/*
Database logs typically include the following logs.
- Error logs - Record errors and warnings related to the database engine.
- Access logs - Contains information about user logins and executed queries.
- Slow Query logs - Highlight long-running or resource-intensive queries.
- Transaction logs - Track changes made to the database.
- Audit logs (if enabled) - Provide details on access and operations performed.
In analyzing database logs, here are a few examples of activities you may want to record:
- SELECT statements for sensitive fields in a database, such as employee compensation or medical records.
- DESCRIBE statements on production databases, which indicate reconnaissance by someone unfamiliar with the database structure.
- Database connections for privileged accounts outside of normal maintenance hours.
You may want to observe the following steps in your investigation.
- Look for failed login attempts or unusual user activity. Use grep or other tools to filter specific events.

- Slow queries or those executed at odd times may indicate malicious behaviour.
grep "SELECT" /var/log/mysql/slow-query.log - Search for input patterns typical of SQL injection.
grep -E "(UNION|SELECT.*FROM|DROP TABLE|OR '1'='1')" /var/log/mysql/general.log - Investigate database errors to understand potential misconfiguration or exploited vulnerabilities.
tail -n 50 /var/log/mysql/error.log - Cross-reference with
/var/log/syslogor /var/log/messages, and/var/log/auth.logto establish unusual activity on the host.

Installed Application Logs
Logs play a critical role in forensic investigations, especially when trying to understand the state of a system and the software it runs. By examining installed applications through the lens of Linux log files, you can trace software installation, updates, and potential malicious activity. Package manager logs are a goldmine for tracking legitimate and potentially unauthorized installations. Each Linux distribution has its own logging mechanisms for package operations.
- Debian-based Systems
- /var/log/apt/* - The history.log file records package installation, upgrade, and removal events. It is particularly useful for identifying recent changes. The term.log file records a detailed output of package operations, including errors or unusual activity.

- Red Hat-based Sytems
- /var/log/yum.log - Tracks installed, updated or removed packages.
- /var/log/dnf.log - Provides similar insights for systems using the DNF package manager
- Arch-based Systems
- /var/log/pacman.log - Offers a chronological view of package-related activities.

Systemd Journal
The relatively new replacement for the SystemV start scripts, systemd, has its own set of logs, many of which replace the traditional ASCII text files found in the /var/log directory. Traditionally, during Linux’s boot process, the OS’s many subsystems and application daemons would each log messages in text files. Different levels of detail would be logged for each subsystem’s messages. When troubleshooting, administrators often had to sift through messages from several files spanning different periods and then correlate the contents. The journaling feature eliminates this problem by centrally logging all system and application-level messages. The systemd-journald daemon is in charge of the journal. It gathers data from several resources and inserts the gathered messages into the diary.
Logs can be stored in memory (volatile) or on disk (persistent). When systemd is using in-memory journaling, the journal files are generated under the /run/log/journal directory. If there is not already such a directory, one will be made. The journal is generated
with persistent storage in the /var/log/journal directory; again, systemd will establish this
directory if necessary. Logs will be written to /run/log/journal in a non-persistent fashion if
this directory is destroyed; systemd-journald will not recreate it automatically. When the daemon is
restarted, the directory is recreated. Below are some of the features of the Journald
log file:
- Tight integration with systemd.
- stderr and stdout from daemons are captured and logged.
- Logs are indexes, making faster searching.
- Logs are in a structured and binary format with well-defined fields.
- Builtin integrity using Forward Secure Sealing (FSS). This signs the logs with one of the generated key pairs. A sealing key will seal the logs at a specified interval, and the verify key can be used to detect tampering. The logs are signed, or sealed, at regular configurable intervals. This provides some level of security for logs.
- journald collects extra log metadata for each log message.
- Journald supports export formats (such as JSON).
Instead of using normal Linux text file utilities to extract information, you have to use
the journalctl utility.
Systemd Journal provides a systemd-journal-remote service that can receive journal messages from other hosts and provide a centralized logging service, in a similar way to the traditional syslog logging, but with a few enhancements.
- TCP-based for stateful established sessions (solves dropped packet issue with UDP).
- Encrypted transmission (HTTPS) for confidentiality and privacy.
- Authenticated connections to prevent spoofing and unauthorized messages.
- Message queuing when the log host is unavailable (no lost messages).
- Signed data with FSS for message integrity.
- Active or passive message delivery modes.
If the systemd-journal-remote service is enabled, you will have to check the configuration file located at /etc/systemd/journal-upload.conf on the client device for the "URL=" parameter containing the hostname of a central log host. On the server, the configuration file can be found at /etc/systemd/journal-remote.conf. This is a forensic artifact that may point to the existence of logs in a different location and may be important on systems where logging is not persistent.
[Remote]
ServerKeyFile=/etc/pki/tls/private/backup.example.com.key
ServerCertificateFile=/etc/pki/tls/certs/backup.example.com.cert
TrustedCertificateFile=/etc/pki/tls/certs/cacert.pemAbove is a sample configuration file for the remote server that will listen for log messages. This provides the details of the TLS keys and certs needed. The systemd-journal-remote user will need to be able to read the private key file. By default, the remote journal service will listen on port 19532 and is configured to listen with https://.
[Upload]
URL=https://backup.example.com:19532
ServerKeyFile=/etc/pki/tls/private/gateway.example.com.key
ServerCertificateFile=/etc/pki/tls/certs/gateway.example.com.cert
TrustedCertificateFile=/etc/pki/tls/certs/cacert.pem
Above is a sample configuration file for the client device. This is similar to the remote service file with only one significant difference, as you can no doubt see. The URL option points to the backup.example.com host on port 19532. Again, the private key must be readable by the systemd-journal-upload user.
Systemd Journal Configuration
From a forensic standpoint, identifying and analyzing the configuration files for the systemd journal is crucial to understanding how logs are managed, stored, and possibly manipulated on a system. The default configuration file locations for the journal are as follows:
- /etc/systemd/journald.conf - This file controls the core behaviour of the journal daemon (journald).
- Check settings related to log storage "Storage=", forward logging "ForwardToSyslog=", rate limiting "RateLimitInterval= and RateLimitBurst=", and compression "Compress=".
- Persistent logs, if configured, are stored in a binary format in /var/log/journal/. If logs are configured to be volatile, they will be stored in /run/log/journal/ and exist only when the system is running and not available for postmortem forensic analysis. If "Storage=none", you might have to look for evidence of intentional log disabling. If "ForwardToSyslog=yes" is set, journal logs are sent to the traditional syslog system on the local machine and stored in local log files (/var/log/) or possibly forwarded to a central log host.
/etc/systemd/journald.conf.d/*.conf- This allows Administrators to create additional configuration files that override or augment journal.conf./usr/lib/systemd/journal.conf- This file contains the system's default configuration. It is used if/etc/systemd/journald.confis missing or incomplete. Compare this with the/etc/systemd/journald.confto understand deviations or overridden defaults.
On systems with a persistent journal, the /var/log/journal/ directory contains a subdirectory named after the machine-id (as found in /etc/machine-id)
that contains the local journal log files. A persistent journal file is named using a combination of the machine-id and random UUID for uniqueness. The magic number identifying a journal file is the initial byte sequence 0x4C504B5348485248 or LPKSHHRH for Linux ext4 file systems.
- 0x4C = L
- 0x50 = P
- 0x4B = K
- 0x53 = S
- 0x48 = H
- 0x48 = H
- 0x52 = R
- 0x48= H
System and user logs are intermingled in journal files allowing for correlation of events across both domains to reconstruct timelines or identify anomalies. System logs are generated by the kernel, system services, and other daemons. Events like service start/stop, kernel errors, boot messages, hardware issues, and more are captured in the system logs. User logs are generated by user-space applications or processes. Below is an example of a system with a machine-id of 47d14209f16640599fe01b64d1d6b05c and the corresponding directory with journal logfiles.

Normal journal logs have a file extension of *.journal. If the system crashed or had an unclean shutdown, or if the logs were corrupted, the filename would end in a tilde (*.journal~ ). Filenames of logs that are in current use, or “online,” are system.journal (for system logs) and user-UID.journal for user logs (where UID is the numeric ID of a user). Log files exist for every user on the system. So user-1000.journal is for one user, user-1001.journal is for another user, and so on. You can find the corresponding username for a user ID by viewing the content of the /etc/passwd file.

Logs that have been rotated to an “offline” or “archived” state
have the original filename followed by @ and a unique string. The unique
string between the @ and .journal is broken into three parts that describe
the content of the log file. Consider the journal filename system@0ce73aa0b0ba42ba9166af1d5a70fd2a-0000000000000001-000626cc4c382958.journal. The anatomy of this filename is broken down as follows:
- system@ - denotes that this system log file has been archived.
- ce73aa0b0ba42ba9166af1d5a70fd2a - Sequence ID.
- 0000000000000001- First sequence number in the file.
- 000626cc4c382958 - Hexadecimal timestamp of the first log entry. The hexadecimal timestamp refers to when the first entry was added to the journal. The value is presented in epoch time. To render in human-readable format, convert this timestamp to decimal, then strip off the last six digits and feed it to an epoch converter. 0x000626cc4c382958 = 173150875419682410. Stripping the last six digits, we obtain 1731508754.

- .journal - Suffix indicating the file type.

Journal logs received over a remote connection typically follow a naming convention that ensures easy identification of the source and timestamp of the logs. A commonly used is remote-hostname-<timestamp>.journal.
The systemd journal logs the system's boot process and correlates logs to individual boots using a 128-bit boot-id. This ensures accurate tracking of events specific to a single boot instance, especially on systems with frequent reboots or troubleshooting needs. The boot-id is a unique 128-bit UUID assigned by the systemd at the start of every boot. It can be found (on a live system) in /proc/sys/kernel/random/boot_id, and used to identify logs from a specific boot session. The bootid is recorded in the journal logs and used to distinguish periods between boots (for example, journalctl --list-boots) and to show logs since the last boot (journalctl -b). The bootid may be of interest during a forensic examination if any malicious activity was known to have occurred during a specific boot period.
Analyzing Journal File Content
The great thing about the journal logging facility is that it is structured, meaning that we can filter information we are interested in easily. With filters, we no longer need to rely on piping logs through commands such as grep and awk. You can use journalctl file and directory flags to specify the location of the journal files to be analyzed.
journalctl --file <filename>
journalctl --directory <directory>
Specifying a file will operate only on that single file. Specifying a directory will operate on all the valid journal files in that directory. Let us look at some interesting logs from system.journal. Here, we view the metadata only.

From the output above, we can view the Machine ID which corresponds to the value stored in /etc/machine-id, and the Boot ID which corresponds to the value contained in /proc/sys/kernel/random/boot_id (see image below). We can also see the timestamp of the first log entry (Head timestamp), as well as the timestamp of the last log entry (Tail timestamp). The Entry objects field indicates the number of logs stored in this file - 48010.

A full extraction of a journal entry can be done with a verbose output (-o verbose) parameter as shown in the image below. You can see that each log contains a wealth of associated metadata. The first line after the log date range information is the cursor position information or the entry’s position in the journal. The rest are key/value pairs with a wealth of filterable data.

Searching journal files is done by including match arguments in the form FIELD=VALUE as shown in the key/value pair in the above image. You need to know the exact value you’re searching for. For example, to extract details about the activities of the user with the UID of 1000 on the system, we run the following command.

Also, let’s say we want to search for any usermod changes that have happened since the last boot. The following command will be helpful. There are no usermod changes in my case as revealed in the output.
The journalctl tool can be used to perform various examination tasks on journal files, but some forensic investigators may prefer to export the journal contents into another format. Two useful output formats are export and json. The new files created are system.journal.json and system.journal.export, which other (non-Linux) tools can easily read. Also, this will aid the use of grep or other text search tools for examiners who prefer their usage.
journalctl --file system.journal -o json > system.journal.json
journalctl --file system.journal -o export > system.journal.export
We said earlier that we can detect whether journal logs have been tampered with. This is done with a feature called Forward Secure Sealing (FSS), which signs the logs with one of a generated key pair. A sealing key will seal the logs at a specified interval, and the verify key can be used to detect tampering. The logs are singed, or sealed, at regular configurable intervals. However, it does not stop adversaries who attack systems and cover their tracks, and they can get around this by either deleting the logs or editing between the sealing time interval. It does not provide any extra information in the event of a threat actor tampering with logs but will give a timeframe in which such an event happened. The integrity of a journal log can be verified as follows. If a journal file has been tampered with, it will fail the verification.
When investigating incidents that happened during a known window of time, extracting logs from an explicit time frame is useful. The journalctl command can extract logs with a specified time range using two flags: -S (since) and -U (until). Any logs existing since the time of -S until (but not including) the time of -U are extracted.

The new features of systemd’s journal mechanism are very much aligned with forensicreadiness expectations. The systemd journal offers log completeness and integrity, which are fundamental concepts in digital forensics.
Post a Comment